O método dos mínimos quadrados e ajustes de funções lineares
Wednesday 29 August 2012 at 4:51 pm
Versão para impressão
Fazer gráficos de um observável em função de outro é bastante comum no dia a dia da pesquisa com o objetivo de se extrair alguma informação deste conjunto de dados. Por exemplo, de um gráfico de velocidade em função do tempo para a queda de um objeto pode-se extrair a aceleração do objeto. Do gráfico da massa em função do volume pode-se extrair a densidade do material. Os exemplos são muitos. Uma vez que os dados estão graficados, a extração das informações relevantes é feita através do ajuste de uma expressão matemática, ou função, a estes dados onde os parâmetros desta função correspondem à grandezas de interessa, tais como a aceleração, densidade, etc. Isso pode ser feito visualmente, com uma régua e intuição, mas atualmente é muito mais simples utilizar programas de análise gráfica. Há muitos disponíveis por ai. Como isso é feito? Qual o procedimento matemático que é utilizado para se determinar qual é o melhor conjunto de parâmetros que, em uma função matemática qualquer, descreve o comportamento dos dados da melhor forma possível? Há vários métodos estatísticos disponíveis. Vamos abordar o método dos mínimos quadrados.
Fazer gráficos de um observável em função de outro é bastante comum no dia a dia da pesquisa com o objetivo de se extrair alguma informação deste conjunto de dados. Por exemplo, de um gráfico de velocidade em função do tempo para a queda de um objeto pode-se extrair a aceleração do objeto. Do gráfico da massa em função do volume pode-se extrair a densidade do material. Os exemplos são muitos. Uma vez que os dados estão graficados, a extração das informações relevantes é feita através do ajuste de uma expressão matemática, ou função, a estes dados onde os parâmetros desta função correspondem à grandezas de interessa, tais como a aceleração, densidade, etc. Isso pode ser feito visualmente, com uma régua e intuição, mas atualmente é muito mais simples utilizar programas de análise gráfica. Há muitos disponíveis por ai. Como isso é feito? Qual o procedimento matemático que é utilizado para se determinar qual é o melhor conjunto de parâmetros que, em uma função matemática qualquer, descreve o comportamento dos dados da melhor forma possível? Há vários métodos estatísticos disponíveis. Vamos abordar o método dos mínimos quadrados.
O método dos mínimos quadrados
Considere um conjunto de dados  onde
onde  são incertezas na variável
são incertezas na variável  (mais a frente vamos ver como tratar casos onde há incertezas também em
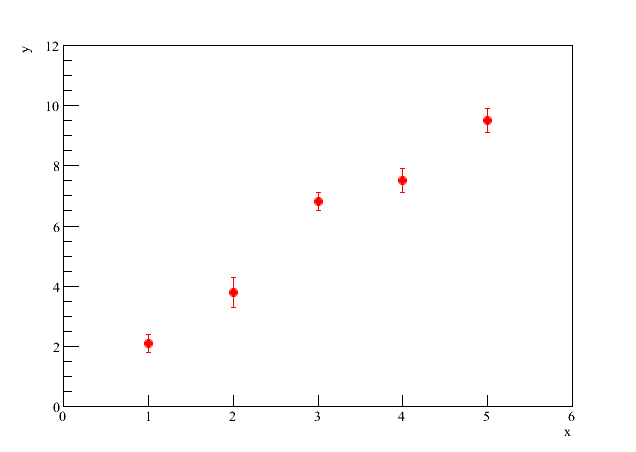
(mais a frente vamos ver como tratar casos onde há incertezas também em  ). Podemos fazer um gráfico de em função de , obtendo algo similar à figura 1.
). Podemos fazer um gráfico de em função de , obtendo algo similar à figura 1.
Figura 1 - Gráfico de em função de
.
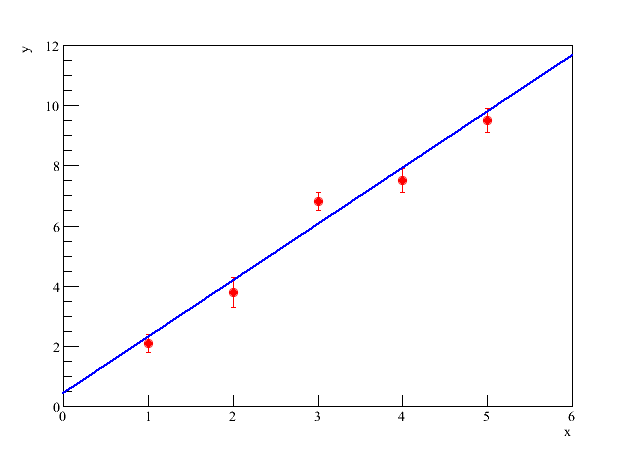
Queremos agora analisar este conjunto de dados e encontrar uma função ") que descreva, estatisticamente, o conjunto de dados tomados, como mostrado na figura 2. Nesta figura,
que descreva, estatisticamente, o conjunto de dados tomados, como mostrado na figura 2. Nesta figura, =ax+b") , é uma reta e, neste caso, queremos encontrar os valores de
, é uma reta e, neste caso, queremos encontrar os valores de  e
e  que melhor descrevem estes dados.
que melhor descrevem estes dados.
Figura 2 - Ajuste de uma reta.
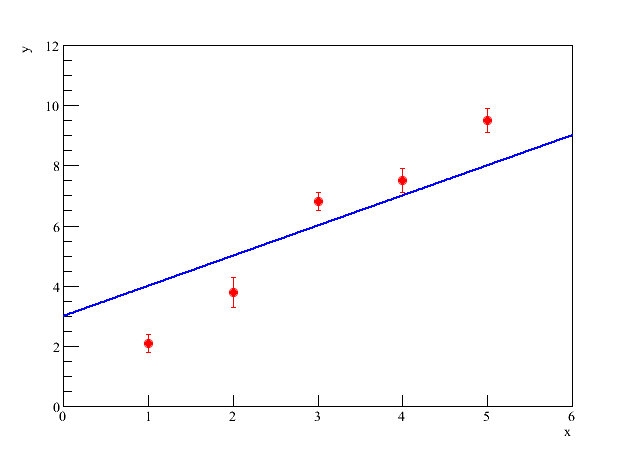
Não são quaisquer valores de e que descrevem os dados. Por exemplo, na figura 3, vemos o mesmo conjunto de dados com uma reta que claramente não descreve o comportamento médio dos dados experimentais.
Figura 3 - Reta com valores de e que não descrevem os dados.
Como determinar os melhores valores possíveis para e ? O método dos mínimos quadrados consiste em um dos métodos disponíveis para fazer esta determinação. Ele se baseia no princípio da máxima verossimilhança que, em linhas gerais, consiste em determinar os valores desses coeficientes que maximizem a probabilidade dos dados serem compatíveis com a função que está sendo ajustada.
Vamos olhar então o nosso conjunto de dados , que consiste em  pontos
pontos  , independentes um do outro. Além disso, os valores de
, independentes um do outro. Além disso, os valores de  possuem funções densidade de probabilidade gaussianas em relação ao seu valor verdadeiro
possuem funções densidade de probabilidade gaussianas em relação ao seu valor verdadeiro  com desvio padrão
com desvio padrão  . Os valores verdadeiros
. Os valores verdadeiros ") dependem do valor de
dependem do valor de  . Neste caso, a probabilidade de se fazer uma medida
. Neste caso, a probabilidade de se fazer uma medida  é proporcional à esta função densidade de probabilidade, ou seja:
é proporcional à esta função densidade de probabilidade, ou seja:
}{\sigma_i}\right)^2\right)}")
Queremos estimar, da melhor forma possível, os valores verdadeiros de tal forma que a probabilidade seja máxima. Vamos tentar descrever os valores verdadeiros por uma função  , que depende de , com
, que depende de , com  parâmetros , a serem determinados, ou seja:
parâmetros , a serem determinados, ou seja:
 = f(x;a_1,a_2,...,a_k)")
No nosso exemplo da reta, acima,  e
e  e
e  . Assim, a a probabilidade de se fazer uma medida pode ser escrita como:
. Assim, a a probabilidade de se fazer uma medida pode ser escrita como:
}{\sigma_i}\right)^2\right)}")
A probabilidade total de encontrarmos o conjunto de dados medido consiste no produto da probabilidade de medir cada ponto , ou seja:

Subsitituindo os valores de probabilidade de cada ponto, lembrando que o produto de exponenciais pode ser transformado em uma soma:
\exp(k_2)...\exp(k_n)=\exp(k_1+k_2+...+k_n)=\exp\left(\sum_{i=1}^{n}k_i\right)")
Concluimos que a expressão para a probabilidade total é:
^n \sigma_1\sigma_2...\sigma_n}\exp{\left( -\frac{1}{2}\sum_{i=1}^{n}\left( \frac{y_i-f(x_i;a_1,a_2,...,a_k)}{\sigma_i}\right)^2\right)}")
A somatória dentro da exponencial é sempre positiva, por conta do quadrado. O sinal negativo nesta exponencial faz com que a probabilidade  seja máxima se o valor da somatória:
seja máxima se o valor da somatória:
}{\sigma_i}\right)^2")
For mínimo. A somatória acima,  , é chamada de chi-quadrado.
, é chamada de chi-quadrado.
Ajustar uma função a um conjunto de dados consiste, então, em determinar os valores dos parâmetros , conhecendo-se a fórmula para ") de modo a minimizar o valor para . Esté é o chamado método dos mínimos quadrados. Note que fizemos duas suposições importantes: a primeira é que os pontos são independentes um dos outros de modo que podemos calcular a probabilidade total como o produto das probabilidades individuais e elas são calculadas independentemente uma das outras. A segunda, mais importante, é que as funções densidade de probabilidade de cada ponto são gaussianas. Sem esta condição, nem sempre é possível maximizar a probabilidade minimizando o .
de modo a minimizar o valor para . Esté é o chamado método dos mínimos quadrados. Note que fizemos duas suposições importantes: a primeira é que os pontos são independentes um dos outros de modo que podemos calcular a probabilidade total como o produto das probabilidades individuais e elas são calculadas independentemente uma das outras. A segunda, mais importante, é que as funções densidade de probabilidade de cada ponto são gaussianas. Sem esta condição, nem sempre é possível maximizar a probabilidade minimizando o .
O método dos mínimos quadrados (MMQ) aplicado a alguns casos
Vamos então aplicar o método dos mínimos quadrados em alguns casos simples:
-
=a") , ou seja, uma função constante;
, ou seja, uma função constante;
-
=ax") , ou seja, uma reta passando na origem;
, ou seja, uma reta passando na origem;
- , ou seja, uma reta qualquer.
O MMQ para uma constante
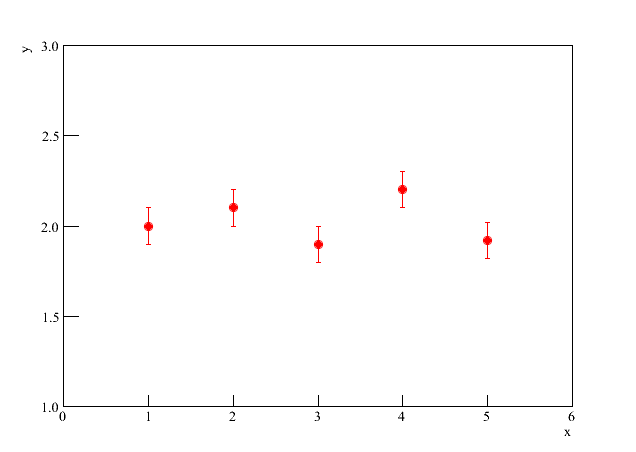
Imagine um gráfico como o da figura 4. Aparentemente é uma constante, independentemente dos valores de . Neste caso, pode ser uma boa expressão para descrever os dados acima.
Figura 4 - Alguns dados a serem ajustados.
Vamos determinar o valor de que maximize a probabilidade de descrever os dados obtidos, utilizando o método dos mínimos quadrados. Para isso, devemos minimizar o valor de . Substituindo na expressão para o , temos:
^2")
Uma função tem o seu valor mínimo em relação a um determinado parâmetro quando a sua derivada em relação àquele parâmetro é nula. Ou seja, para achar o valor de que minimize o devemos fazer:

Calculando a derivada, temos:
^2\right) = -2 \sum_{i=1}^{n}\frac{1}{\sigma_i}\left( \frac{y_i-a}{\sigma_i}\right) = -2 \sum_{i=1}^{n}\left( \frac{y_i-a}{\sigma_i^2}\right)")
Para esta derivada ser nula, a somatória deve ser nula, ou seja:
 = \sum_{i=1}^{n}\left( \frac{y_i}{\sigma_i^2}\right) - a\sum_{i=1}^{n}\left( \frac{1}{\sigma_i^2}\right)")
Isolando , chegamos à:
}{ \sum_{i=1}^{n}\left( \frac{1}{\sigma_i^2}\right)}")
Podemos ainda reescrever a expressão acima, fazendo a substituição  , que resulta em:
, que resulta em:

Ou seja, o valor de corresponde à média dos valores de ponderados pelo inverso do quadrado das incertezas. Isso é razoável de se entender: pontos com incertezas pequenas (mais precisos) possuem peso maior e, neste caso, o valor de vai ficar mais próximo desses pontos. Pontos com elevada incerteza possuem pouco peso e, consequentemente, são pouco considerados no cálculo da média.
Na figura 5 mostramos a função ajustada aos dados da figura 4. Note como os dados ficam distribuídos em torno da constante ajustada.
Figura 5 - Constante ajustada aos dados.
Um caso interessante é aquele em que todas as incertezas são iguais. Neste caso  , que pode ser isolado para fora das somatórias, resultando em:
, que pode ser isolado para fora das somatórias, resultando em:

Que corresponde ao cálculo de uma média simples dos valores de .
O MMQ para uma reta passando na origem
Imagine agora a situação na qual a função que queremos ajustar aos dados seja uma reta que passa na origem, . Devemos então achar a constante , que é o coeficiente angular da reta, utilizando o MMQ. Neste caso, o pode ser escrito como:
^2")
Note a diferença entre esta expressão para o e a utilizada no caso anterior. Mais uma vez, a minimização do para encontrar a constante ocorre quando:
Calculando a derivada, temos:
^2\right)")
 = -2 \sum_{i=1}^{n}\left( \frac{x_iy_i-ax_i^2}{\sigma_i^2}\right)")
Como esta derivada deve ser nula para minimizar o temos que:
")
 - a\sum_{i=1}^{n}\left( \frac{x_i^2}{\sigma_i^2}\right)")
Ou seja:
} {\sum_{i=1}^{n}\left( \frac{x_i^2}{\sigma_i^2}\right)}")
O MMQ para uma reta qualquer
No caso de uma reta genérica, , devemos encontrar os valores de e que minimizam, simultaneamente, o dos dados obtidos em relação a esta função. Seguindo os exemplos anteriores, a expressão para o pode ser escrita como:
}{\sigma_i}\right)^2")
Para encontrar os valores de e fazemos então:

Note que agora temos um sistema de duas equações para resolver. Mas também temos duas incógnitas, e . Então não há problemas. A única diferença e o maior grau de dificuldade algébrica, neste caso.
Vou deixar como exercício a resolução das duas derivadas acima e também a resolução do sistema de equações que surge. É muito interessante que isso seja feito com calma e atenção. O MMQ é uma importante ferramenta de análise de dados e vai estar presente no dia a dia nosso. Resolvendo o sistema de equações encontra-se que:


Sendo os valores  somatórias definidas como:
somatórias definidas como:





Na figura 6 é mostrado um gráfico com pontos experimentais ajustados a uma reta pelo MMQ. Note que a reta fica bastante próxima dos pontos experimentais que têm incertezas pequenas (são mais precisos). Embora isso não fique muito evidente nas expressões que deduzimos acima, a justificativa é a mesma que utilizamos no primeiro caso, do ajuste de uma constante. Note que, nas somatórias, sempre pesamos os termos pelo inverso do quadrado das incertezas. Ou seja, menores incertezas, maiores pesos nas somatórias. É por conta disso que, tão importante quanto saber medir os valores experimentais, é saber estimar as incertezas dos valores medidos. Só assim pode-se fazer uma análise estatística confiável.
Figura 6 - Ajuste de uma reta a pontos experimentais.
Incerteza dos parâmetros ajustados
Note que, como os parâmetros das funções são extraídos de um conjunto de dados, é natural pensar que flutuações estatísticas neste conjunto de dados afetem os valores dos parâmetros ajustados. Se repetirmos o mesmo experimento, com o mesmo procedimento, várias vezes, é natural imaginar que, a cada vez, um conjunto de parâmetros diferente será extraído. Ou seja, os parâmetros extraídos também estão sujeitos a flutuações e, consequentemente, possuem incertezas. Como obter as incertezas dos parâmetros ajustados?
A incerteza dos parâmetros ajustados pode ser obtida através de propagação de incertezas. Sendo uma função ") onde cada medida possui uma incerteza , a incerteza de pode ser calculada através de:
onde cada medida possui uma incerteza , a incerteza de pode ser calculada através de:
^2\sigma_i^2}")
Nos nossos casos, o parâmetro ajustado depende dos valores dos pontos experimentais, ") e das incertezas nos pontos, . Nesse caso, considerando que há apenas incertezas nos valores de (veremos mais a frente o que fazer quando há incertezas em ). Não consideramos também que as incertezas são estimadas e, portanto, também estariam sujeitas a flutuações. Sendo assim, devemos aplicar a fórmula de propagação de incertezas somente em relação aos valores de dos dados ajustados.
e das incertezas nos pontos, . Nesse caso, considerando que há apenas incertezas nos valores de (veremos mais a frente o que fazer quando há incertezas em ). Não consideramos também que as incertezas são estimadas e, portanto, também estariam sujeitas a flutuações. Sendo assim, devemos aplicar a fórmula de propagação de incertezas somente em relação aos valores de dos dados ajustados.
Incerteza no ajuste de uma constante
Como vimos acima, se fizermos um ajuste de uma constante, ou seja, , aos dados, o MMQ resulta em:
com . Neste caso, aplicando-se a fórmula de propagação de incertezas, temos que:
^2\sigma_j^2}")
Calculando-se a derivada parcial em relação a um valor qualquer de  , obtemos que:
, obtemos que:

Substituindo essa expressão na fórmula de propagação para a constante, obtem-se:
^2\sigma_j^2} = \sum_{j=1}^{n}{\left(\frac{ p_j}{ \sum_{i=1}^{n} p_i}\right)^2\frac{1}{p_j}}")
^2} = \frac{1}{\sum_{i=1}^{n} p_i}}")
Ou seja:

Note que, na expressão acima, se as incertezas de todos os pontos forem iguais, ou seja,  , ela se reduziria à:
, ela se reduziria à:

que é a expressão para o desvio padrão da média. Esse resultado está de acordo com o fato de que, sendo todas as incertezas iguais, o valor ajustado corresponde à média simples de todos os pontos, como discutimos anteriormente.
Incerteza no ajuste de uma reta passando pela origem
No caso de um ajuste de uma reta passando na orígem, , a constante , conforme deduzimos, vale:
A derivada parcial dessa expressão em relação à vale:
}")
Substituindo essa derivada na expressão para propagação de incertezas, como fizemos no caso do ajuste de uma constante, obtém-se que, após alguma manipulação:
}")
Incerteza no ajuste de uma reta qualquer
No caso de uma reta qualquer, , os parâmetros ajustados são dados por:
Sendo os valores somatórias definidas anteriormente. Usando o mesmo princípio que nos casos anteriores de propagação de incertezas, considerando apenas as grandezas como possuindo incertezas, é fácil chegar em (faça como exercício):


No caso de um ajuste com mais de um parâmetro, é comum que estes parâmetros não sejam independentes um do outro. Ou seja, pode haver covariância entre eles. No caso de uma reta isso é simples de entender. Um pequeno aumento no valor de , por exemplo, força que o valor de diminua de modo a tentar manter o minimizado. E vice-versa: uma diminuição de força um aumento em . Ou seja, estes parâmetros não são independentes. Em momento oportuno eu pretendo escrever um texto mais formal sobre covariâncias e tocarei neste assunto novamente. Por hora, caso seja necessário, a covariância entre esses parâmetros pode ser facilmente calculada através de:
 = \frac{S_x}{S_\sigma S_{x^2} - S_x S_x}")
Ajustes com incertezas na variável x
O MMQ que desenvolvemos até aqui supôs que  ou seja, não há incertezas nas variáveis . Mas em muitas situações práticas, tanto as variáveis quanto possuem incertezas. O método formal para isso é chamado de método dos mínimos quadrados totais (ver esse link). Vamos aqui tentar simplificar um pouco e tentar compreender a ideia por trás de uma minimização onde consideramos incertezas em e .
ou seja, não há incertezas nas variáveis . Mas em muitas situações práticas, tanto as variáveis quanto possuem incertezas. O método formal para isso é chamado de método dos mínimos quadrados totais (ver esse link). Vamos aqui tentar simplificar um pouco e tentar compreender a ideia por trás de uma minimização onde consideramos incertezas em e .
No MMQ somente com incertezas em nós calculamos os resíduos entre os pontos experimentais e a função ajustada, dados por:
}{\sigma_i}")
de modo que o chi-quadrado é calculado da soma de todos os resíduos ao quadrado, ou seja:

que é posteriormente minimizado em relação aos parâmetros livres da função ") .
.
O que estamos fazendo, quando obtemos os resíduos desta forma, é calcular a "distância" entre os pontos experimentais e a função ajustada em unidades de incerteza. Quando só há incerteza em , a incerteza da diferença entre e ") é dada pela própria incerteza em ou seja, .
é dada pela própria incerteza em ou seja, .
Quando há incerteza em , a o valor da função em está sujeita a uma incerteza. Sabendo que a diferença entre o ponto experimental e a função ajustada pode ser escrita como:
")
A incerteza nesta diferença é:
}^2 = \sigma_i^2 + \left(\frac{\partial f}{\partial x}\right)^2\sigma_{x_i}^2")
Deste modo, os resíduos podem ser calculados como:
}{\sqrt{\sigma_i^2 + \left(\frac{\partial f}{\partial x}\right)^2\sigma_{x_i}^2}}")
De modo que o chi-quadrado, finalmente, pode ser escrito como:
)^2}{\sigma_i^2 + \left(\frac{\partial f}{\partial x}\right)^2\sigma_{x_i}^2}}")
Que deve ser minimizado em relação aos parâmetros livres da função . Note que isso é agora muito mais complexo, pois há um termo de uma derivada de , o que complica bastante a resolução algébrica do problema. Programas de computadores lidam com isso sem muitos problemas, seja resolvendo precisamente o problema de mínimos quadrados totais, seja através de métodos numéricos. Por outro lado, podemos nos encontrar em uma situação na qual não temos à disposição um programa para fazer a regressão total ou o que temos considera apenas incertezas em . Neste caso, podemos aplicar uma receita simples que funciona na grande maioria dos casos práticos do nosso dia a dia:
- Faça o ajuste da função considerando apenas as incertezas em , ou seja, assuma que
 .
.
- De posse dos parâmetros ajustados, calcule incertezas "efetivas" para dadas por:
_{\text{efetiva}} = \sigma_i^2 + \left(\frac{\partial f}{\partial x}\right)^2\sigma_{x_i}^2")
- Faça novamente o ajuste da função considerando agora que as incertezas em são as efetivas, calculadas no passo (2).
- De posse dos novos parâmetros ajustados, repita os passos (2) e (3) até que a diferença entre uma repetição e a anterior para os valores dos parâmetros ajustados seja pequeno, se comparada à incerteza desses parâmetros.
É um método trabalhoso mas com uma ou duas interações, em geral, a resposta converge e o resultado é bastante satisfatório do ponto de vista prático.
Parabéns pelo ótimo artigo. Ele deixou o assunto bem mais claro e simples para mim.